· Alexander · Homelab · 10 min read
Rebuilding My Home Lab
Rebuilding my homelab 'cluster' into a proper 'cluster'.

It’s been a while since I last posted about my homelab or well posted on the blog. So I figured I’d start off with a banger for 2025. Rebuilding my homelab into a Docker Swarm cluster that supports high availability. Hope you’re ready for a ride, because this was definitely a journey. 😅
Side note: I also recently acquired a Bambu Lab A1 3D printer (with the AMS :)) to replace my old Anet A8. I’d say it’s mine, but I’ve only been printing stuff for my wife so far..The Plan
The plan for this project was to:
- Create a cluster that supported high availability ✅
- Setup a distributed storage solution that supported the above ✅
- Setup a load balancer ✅
- Have the cluster communicate over 2.5gb or faster networking ✅
- Have a minimum of 3 nodes ✅
- Be small and efficient ✅
Easy enough right?… right?
Since I had two Dell Optiplex 5050 Micros that I was using already, I decided to grab a third micro to complete the 3 node cluster. As for the actual orchestration software I decided to stick with Docker and use Docker Swarm. I’m a Docker guy but never had a chance to use Swarm properly with a shared storage system. Figured it was time to give it a proper go.

Current v2 Cluster Specs
- 2x Dell Optiplex 5050 Micros
- i5-7600T, 16GB RAM
- 1x Dell Optiplex 7040 Micros
- i5-6500T, 16GB RAM
- 3x Realtek 8125B 2.5gb A+E NICs
- 3x Intel 700p 256GB SSDs
- 3x Crucial BX500 1TB SSDs
- Ubiquiti Flex-2.5g Switch
- Ubuntu 24.04 LTS
- GlusterFS
Cluster v1
circa 2023Cluster v1 never actually made it to ‘production’. It ended up being a test bed and a learning experience on gotchas when it came to Linux, Intel, drivers, and poor research on my part…
TLDR: I originally bought some Intel i225-v 2.5gb m.2 cards from IOCrest thinking they’d work. Come to find out these particular chips have some driver issues on Linux (specifically Ubuntu).
When originally designing the cluster I had planned on using M.2 2.5g cards since the Micro’s had M.2 M-key slots. That way I could get a less expensive SATA SSD for storage. After doing some research I settled on some Intel 225-V 2.5g cards from IOCrest on AliExpress. The one downside to these cards was the vertical connector pins. The chassis did not have enough space with a SATA SSD installed. So I did what any tinkerer would do and replaced the pins with right angle ones. The first two cards went good, but my old soldering iron doesnt keep temp well. On the third card’s NIC module I messed up and destroyed one of the traces. So I had to fix it with a jumper wire. Live and learn I suppose.
As for the NICs themselves, I started experiencing driver issues after getting two of the nodes up and running in a ‘mock’ swarm. These issues manifested as random disconnects or complete NIC power loss. I tried to fix it by messing with grub configs for pcie_aspm thinking it was related to Active State Power Management (ASPM) at first. I then tried manually setting the autonegotiation via ethtool. Also double checked UEFI settings, etc. Nothing seemed to work. So I ended up scrapping the Intel cards and going with Realtek 8125B cards for cluster v2.
Anyways, I’ll leave you with a few pictures from the v1 prototype, and we can move on to v2.
Cluster v2
circa 2024My second attempt at the cluster faired a bit better. Well mostly (more on that later). After my first purchase mistake I went back and bought different M.2 adapters. These were A+E keyed and used the WLAN slot rather than the M.2 M-keyed slot which got freed up for more storage. These new adapters also use a Realtek chipset (8125B) rather than an Intel one. So no more odd driver issues.
 M.2 A+E keyed adapter installed
M.2 A+E keyed adapter installed
With the new adapters using the A+E slot, I decided to use the M slot for a boot drive and the SATA port for cluster storage. For the boot drive I went with some Intel 700p 256GB SSDs I bought off someone from the Ubiquiti Discord server. As for cluster storage I went with 1TB Crucial BX500 SSDs from Amazon. These are not the fastest drives by any means but for my use case they should do just fine.
 Storage SSDs
Storage SSDs
There was one downside to the Intel SSDs though. Their physical size. They are 2230 and the Micro chassis only supports 2260 and 2280. So in order to use them I had to print out some 2230 to 2280 adapter brackets. I also printed out a 2.5in tray for the third Micro since it did not come with one. The print files are linked below.
- 2230 to 2280 m.2 adapter ssd by nzalog via Thingiverse
- Dell Optiplex micro 2.5” SSD / HDD Caddy via Thingiverse
- 3D printed NIC ears via Thingiverse
The OS
For the OS I decided to stick with my tried and true Ubuntu Server (24.04 LTS btw). It’s stable and easy to manage. Though, I may eventually re-image to Rocky Linux for easy live patching when I rebuild again. The process was pretty standard. I booted via my netboot.xyz PXE server, ran through the installer and then used Ansible to configure the OS. I’ll have the playbooks + task files in the blog-files repo after this post is live.
Ansible playbook running on the cluster nodesNetworking
After the OS was set up on all the nodes, I went ahead configured the network interfaces. During the v2 build Ubiquiti launched their Flex 2.5g switch line. Since this was an SFF cluster the Flex Mini 2.5g was a perfect fit as the cluster’s network backbone. Also with it being powered by POE made for one less cable to deal with. The cluster network is also a fairly simple one. It has no access to the internet and no access to any other networks. Other networks also can’t access it. Don’t need stuff snooping on my unencrypted SQL traffic..
With the network interfaces configured and working, it was time to test the speed using iperf. As you can see by the short video below, I was able to get roughly 2.5gbps of bandwidth between the nodes.
iperf testingDistributed File System
This was probably the most difficult part of the cluster build. At the time I had really no experience dealing with distributed file systems. I narrowed down my options to GlusterFS and Ceph. I ended up going with GlusterFS for this iteration. Using the official documentation I was able to get a basic cluster up and running fairly quickly. I also created a dedicated Docker user ‘doc’ and set its home directory to the GlusterFS volume on each of the nodes. I thought this would be a great idea, but it ended up being a pain later on.
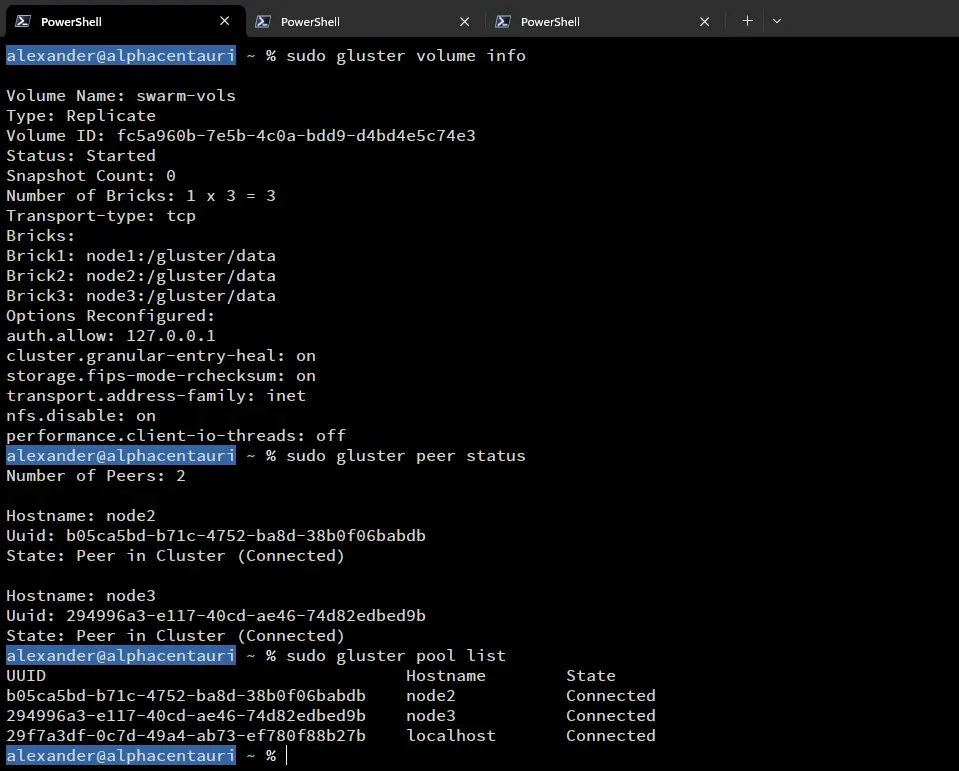 GlusterFS setup
GlusterFS setup
Docker Swarm
With the OS, Networking, and DFS setup, it was time to set up Docker Swarm. Setting up Docker and Docker Swarm is fairly straight forward using the official documentation. You basically follow the installation on each of the nodes. Then you initialize the swarm on one and join the other nodes to it. In my case my commands were:
sudo docker swarm init --advertise-addr 192.168.100.2 ## init the swarm on the cluster network interfacesudo docker swarm join --token SWMTKN-1-4c2d6gncjh15gaznem5m8t2twwfn09o0paqpjxwdkqr1n76h8j-chr42vcbaobx7v2nrk86q9e93 192.168.100.2:2377 ## joining other nodes to the swarmI then promoted the other two nodes to managers. This way I had proper high availability as it requires a minimum of 3 managers to be in the swarm.
 Docker Swarm cluster
Docker Swarm cluster
Keepalived
Next up was setting up Keepalived to handle VRRP for the cluster. This allowed me to have a single IP address that automatically failed over to the next node automatically. The video below shows the failover in action (sped up to keep the video short).
Keepalived VRRP failoverAs you can see the active node switches as each keepalived service is terminated. The lower right shows a constant ping to the VRRP virtual IP (VIP). In this case 10.8.8.11. Having this VIP allows me to bring down hosts for maintenance or updates without having to worry about service connectivity.
HA Caddy
The final step before I could start using the cluster was to set up a load balancer/reverse proxy. There are a few different options but, if you’ve read any of my previous posts you know I love using Caddy. With its easy-to-use configuration and automatic certificate management makes it hard to beat. Also, Caddy is a great choice for this since it automatically clusters itself if all instances use the same storage volume.
First thing I did was create the new overlay network for Caddy. This network would be for any services that I wanted to be able to access from outside the cluster.
sudo docker network create --opt encrypted=true --driver overlay --attachable --internal --subnet=172.0.96.0/20 caddy-internalCreating the Caddy service file.
services: caddy: deploy: replicas: 3 restart_policy: condition: on-failure placement: constraints: - node.role == manager networks: - caddy - auth image: alexandzors/caddy:2.9.1 env_file: .env ports: - 81:80 - 443:444 - 444:443 - 2019:2019 volumes: - /swarm/volumes/doc/caddy/Caddyfile:/etc/caddy/Caddyfile:ro - /swarm/volumes/doc/caddy/.data:/data - /swarm/volumes/doc/caddy/configs:/etc/caddy/configs:ro - /mnt/plex:/srv:ro
networks: caddy: name: caddy-internal external: true auth: name: auth-internal external: trueThen deploying Caddy to the swarm.
sudo docker stack deploy --c caddy.yml caddy docker service ls command showing Caddy running on all 3 nodes
docker service ls command showing Caddy running on all 3 nodes
I eventually need to update the Caddy deployment to use host mode for port assignments. That way I can get the source IP address of incoming requests and not the docker proxy IP. But that will be part of v3.
Cluster v3
circa 2025So here we are. Cluster v2 has been running great for a while now, but I’ve been having some issues with it. The main, and arguably the largest, issue I have been running into is the slow performance of GlusterFS. I’m not sure if it’s the hardware choices I made, or a misconfiguration? I tried the performance tuning tips from the official documentation but was still running into issues. Like switching to the cluster user ‘doc’ would take anywhere from 30 to 45 seconds to complete. Also, deploying stacks of services could take up to 5 minutes before they were alive and running.
Either way for v3 I’m probably going to move to Ceph as my DFS solution. Since it seems to be the more popular of the two after digging around more. I may need to upgrade the RAM on the nodes to handle it though. I’m also going to try and add a 4th node to the cluster with beefier hardware since I still have one 2.5g port left on the switch. Maybe one with some GPU compute to handle local LLMs?
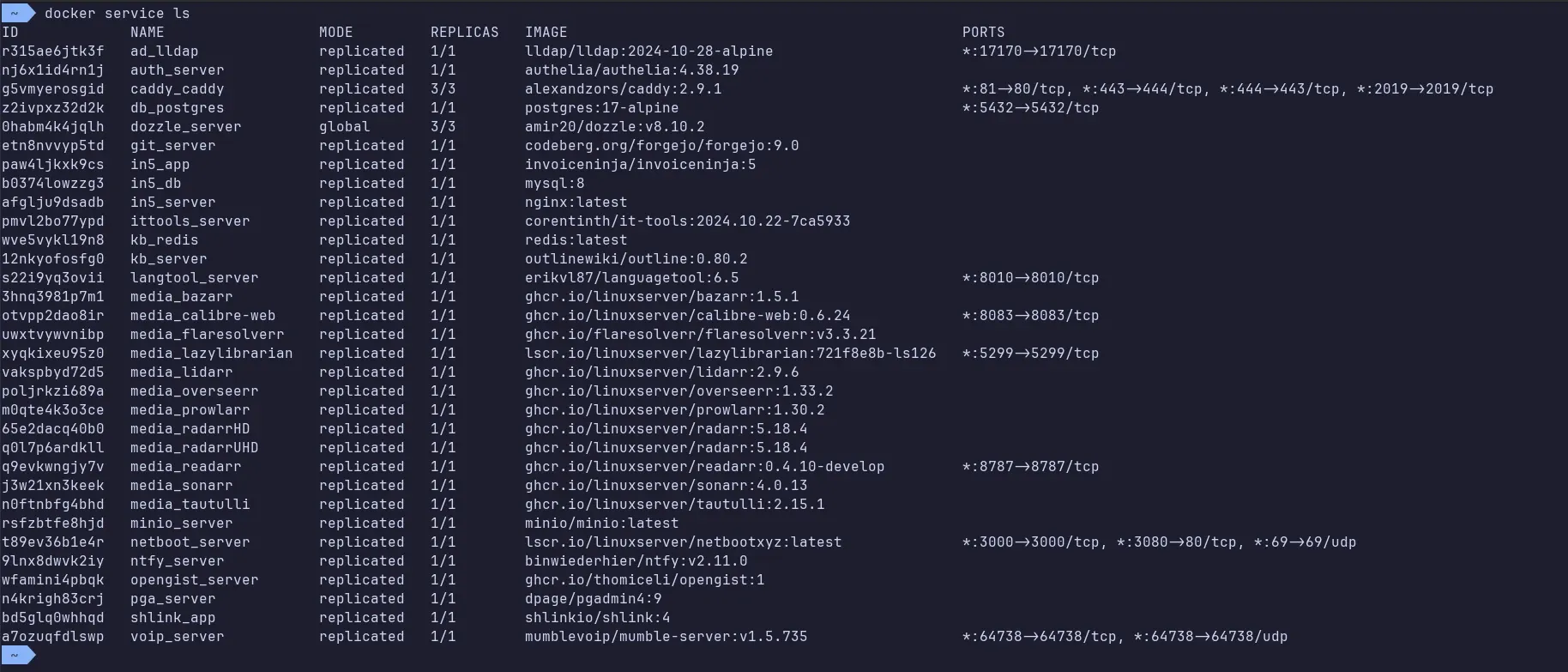 Current services running on the cluster
Current services running on the cluster
However, what won’t be changing is my use of Docker Swarm. 😉